الگوریتم K-Means چیست؟
الگوریتم K-Means یکی از الگوریتمهای معروف در دادهکاوی و یادگیری ماشینی برای خوشهبندی دادهها است. هدف اصلی این الگوریتم تقسیم مجموعه داده به چند خوشه به نحوی است که اعضای هر خوشه به یکدیگر شبیه باشند و اعضای مختلف خوشهها از یکدیگر متمایز باشند.
این الگوریتم در دههی 1950 میلادی توسط Stuart Lloyd ابتدا به عنوان یک الگوریتم برای کمینه سازی مجذور فاصلهها میان نقاط (به عنوان معیار انتخاب میانگینها) در دامنهی مهندسی سیگنال و کمینهسازی انتقال اطلاعات ارائه شد. او این الگوریتم را به عنوان "تجزیه و تحلیل وابسته به وقت تاخیر" معرفی کرد. اما از آن زمان تا تاجیک الگوریتم K-Means به عنوان یکی از الگوریتمهای مهم در خوشهبندی دادهها شناخته شد.
در دههی 1960، دو محقق به نامهای James MacQueen و J.B. Kruskal به طور مستقل به توسعه و بهینهسازی الگوریتم K-Means پرداختند. این الگوریتم به عنوان یک الگوریتم خوشهبندی به مجموعه متنوعی از حوزهها و مسائل اعم از شبکههای عصبی مصنوعی، دادهکاوی، تجزیه و تحلیل متن و تصاویر، بهینهسازی توابع و حتی طبیعت بستگی دارد.
این الگوریتم به طور گسترده در صنایع مختلف از جمله اقتصاد، پزشکی، شبکههای اجتماعی، تحلیل رفتار مشتریان و سیستمهای پیشنهاد گذاری مورد استفاده قرار میگیرد. از آن زمان تا به امروز، تحقیقات بسیاری در زمینه بهبود و توسعه الگوریتم K-Means و نسخههای متعدد از آن انجام شده است تا از کارآیی و کاربردهای این الگوریتم در دنیای دادهها بهرهبری شود.
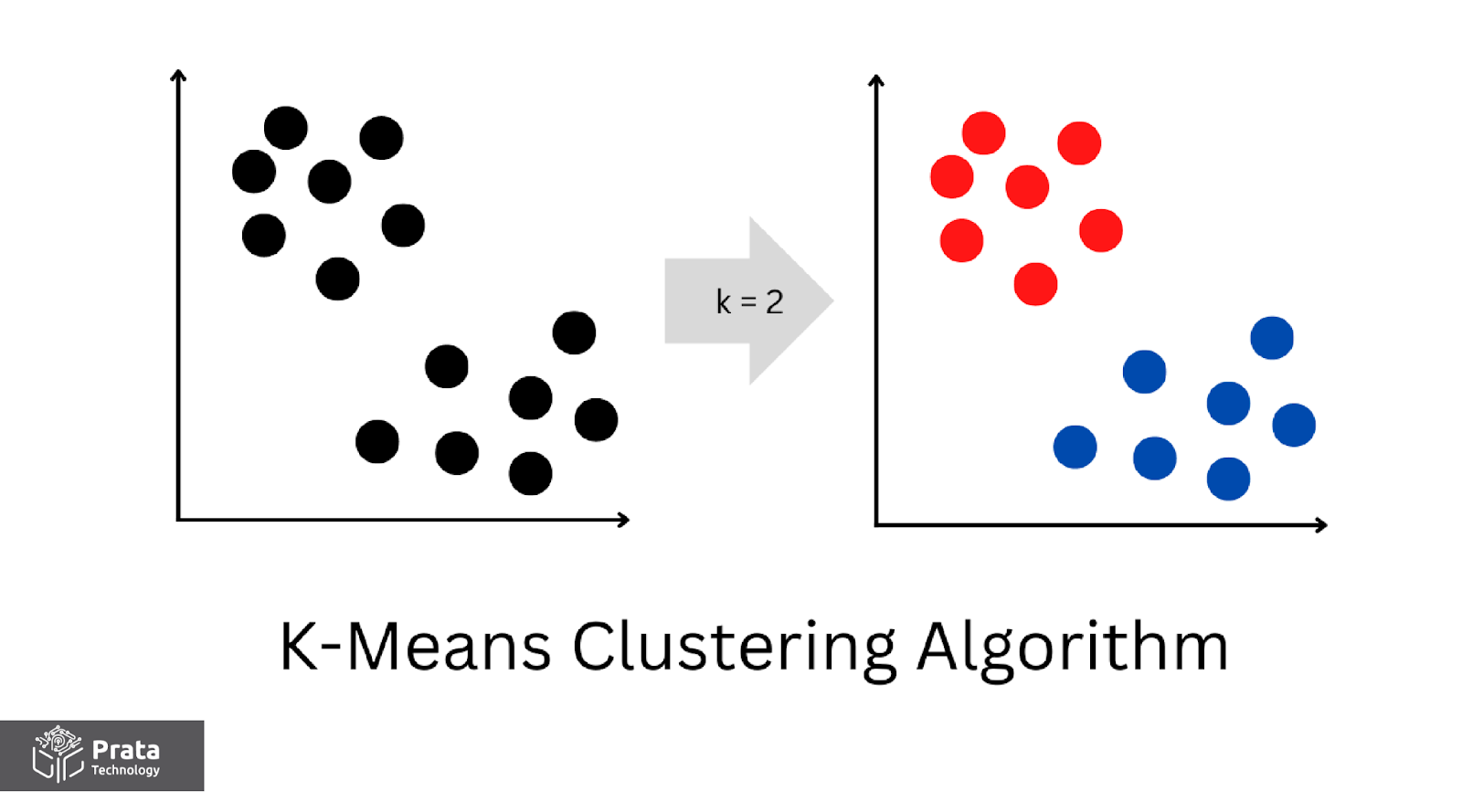
نحوه عملکرد الگوریتم K-Means
الگوریتم K-Means به صورت زیر عمل میکند:
- انتخاب تعداد خوشهها: ابتدا تعداد خوشههای مورد نظر برای تقسیم دادهها باید مشخص شود.
- انتخاب نقاط مرکزی اولیه (مراکز خوشهها): نقطه به صورت تصادفی انتخاب میشود تا به عنوان مراکز خوشهها شروع به کار کنند.
- تخصیص هر نقطه به نزدیکترین مرکز خوشه: هر نقطه به نزدیکترین مرکز خوشه تخصیص داده میشود. این تخصیص بر اساس معیار فاصله میان نقاط (مثلاً فاصله یا میانگین مربعات فاصله) انجام میشود.
- به روزرسانی مراکز خوشه: مراکز خوشه با میانگین مختارات نقاطی که به هر خوشه تخصیص پیدا کردهاند، به روزرسانی میشوند.
- تکرار مراحل 3 و 4 تا همگرایی: مراحل تخصیص نقاط به خوشهها و بهروزرسانی مراکز خوشه تا زمانی ادامه می یابد که دیگر تغییری در تخصیص نقاط اتفاق نیفتد یا تا حداکثر تعداد تکرارهای مشخص شده.
- خوشه بندی نهایی: در نهایت، دادهها به تعداد خوشه های مورد نظر خوشه بندی می شوند و مرکز هر خوشه نیز به عنوان نقطه مرکزی آن خوشه انتخاب میشود.
K-Means یک الگوریتم سریع و مؤثر برای خوشه بندی دادهها است و در مسائل مختلفی از جمله تجزیه و تحلیل داده، تحلیل متن و تصاویر، و مدیریت مخزن داده مورد استفاده قرار میگیرد.
کاربردهای الگوریتم K-Means در حوزه های مختلف
الگوریتم K-Means به عنوان یکی از معروفترین و کارآمدترین الگوریتمهای خوشهبندی داده در حوزههای مختلف کاربردهای وسیعی دارد. در زیر به برخی از کاربردهای این الگوریتم در حوزههای مختلف اشاره میشود:
- تجزیه و تحلیل داده: در علوم داده، از این الگوریتم برای تجزیه و تحلیل دادهها و شناسایی الگوها و خوشههای موجود در دادهها به کار میرود. این کاربرد معمولاً در مطالعات بازاریابی، تحلیل متن، و شناسایی الگوهای رفتاری مشتریان مورد استفاده قرار می گیرد.
- تقسیم تصاویر و ویدئوها: این الگوریتم برای تقسیم تصاویر و ویدئوها به قسمتهای مختلف (خوشه بندی تصاویر) استفاده میشود. این کاربرد رایج در پردازش تصویر، تحلیل تصاویر پزشکی، و دستهبندی اشیاء در ویدئوها میباشد.
- بهبود سیستم های توصیه گر: از این الگوریتم برای پیشنهاد دهی محتوا و محصولات به کاربران در سیستمهای توصیهگر (مانند Netflix و Amazon) به کار میرود. این الگوریتم کاربردی در افزایش تجربه کاربری و افزایش فروش آنلاین است.
- شناسایی تغییرات و نقطه تغییر: این الگوریتم میتواند به عنوان یک روش برای تشخیص تغییرات در دادهها و نقاط تغییر (change points) مورد استفاده قرار گیرد. این کاربرد در کنترل پروسههای صنعتی و تحلیل دادههای سیگنالی از اهمیت بسیاری برخوردار است.
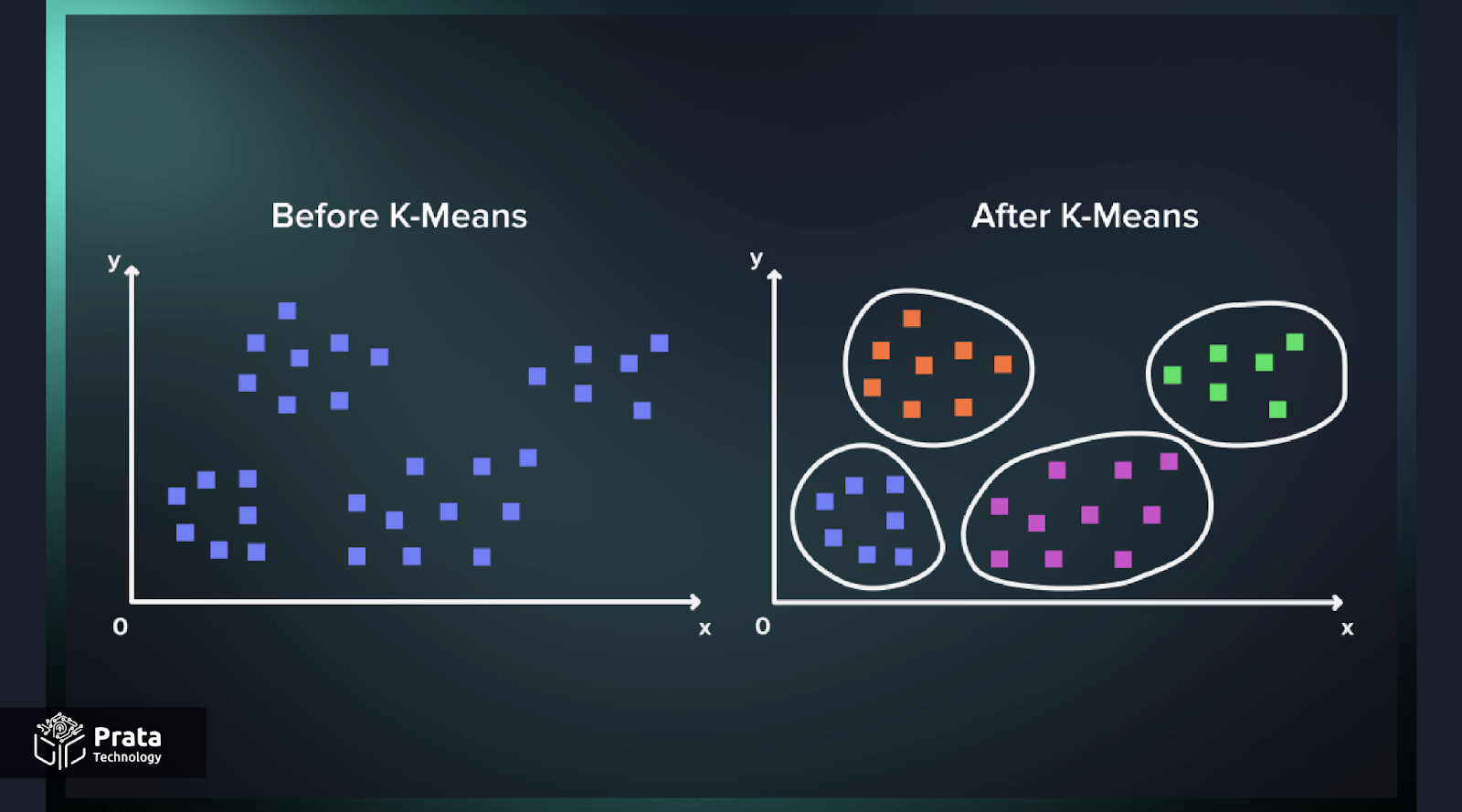
تجزیه و تحلیل فیزیکی و شیمیایی:
K-Means برای تجزیه و تحلیل دادههای فیزیکی و شیمیایی مورد استفاده قرار میگیرد، از جمله طیفسنجی ماسههای معدنی، شناسایی ترکیبات شیمیایی، و تجزیه تصاویر رزونانس مغناطیسی هستهای (MRI).
بازشناسی الگو در معماری و طراحی:
K-Means به عنوان یک ابزار برای بازشناسی الگوهای معماری و طراحی مورد استفاده قرار میگیرد، از جمله شناسایی خوشههای مشابه در نقشههای معماری و پروژههای طراحی.
دستهبندی متن و محتوا:
در پردازش متن و دادههای متنی، K-Means برای دستهبندی متن و تقسیم اسناد به دستههای مشابه به کار میرود. این کاربرد معمولاً در جستجوی اطلاعات، دستهبندی خبرها و تحلیل متنهای اجتماعی مورد استفاده قرار میگیرد.
بهینه سازی مسائل توزیع:
الگوریتم K-Means در بهینه سازی تخصیص منابع در شبکه ها، بهینه سازی مسائل توزیع و تخصیص منابع مورد استفاده قرار می گیرد.
تعداد کاربردهای این الگوریتم بسیار بیشتر از این است و این الگوریتم به عنوان یک ابزار کلیدی در تحلیل داده ها و انجام وظایف خوشه بندی به عنوان یک بخش مهم از داده کاوی و یادگیری ماشینی شناخته میشود.
خلاصه مقاله
الگوریتم K-Means یکی از الگوریتمهای معروف در داده کاوی و یادگیری ماشینی جهت خوشه بندی داده میباشد.هدف اصلی این الگوریتم تقسیم بندی مجموعه ای از داده ها میباشد به صورتی که اعضای هر خوشه به یکدیگر شبیه و اعضای مختلف خوشه ها از یکدیگر متمایز باشند.از این الگوریتم در دسته بندی محتوا، بهینه سازی مسائل توزیع و تجزیه و تحلیل فیزیکی و شیمیایی و... استفاده می شود.